Flooding is no longer just an engineering or emergency response issue. For urban planners, it is becoming a land-use, infrastructure, and development control challenge — and machine learning is emerging as a powerful screening layer to guide flood-smart decisions.
A two-stage machine learning framework
A recent study by H2O Datatech presents a two-stage machine learning framework that can help planners better understand where flood risks are likely to emerge, why certain areas are more vulnerable, and how urban development patterns may influence future flood exposure.
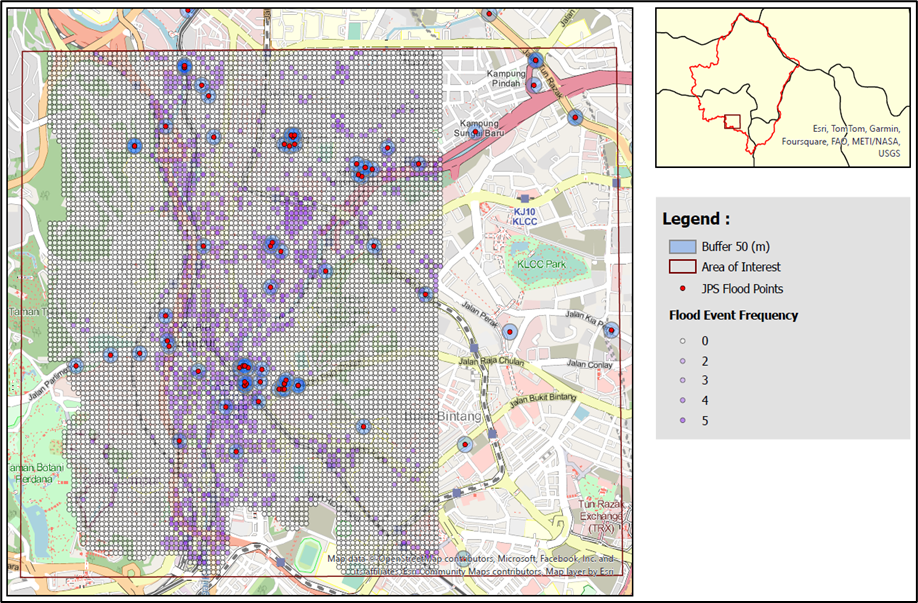
The framework was applied to the Jambatan Sulaiman watershed, covering Kuala Lumpur and parts of Selangor. Instead of looking only at river levels, the model combines climate, land use, soil, and topographic data to produce high-resolution flood inundation insights at a 30-metre grid scale.
How the model works
The first stage predicts streamflow using a Random Forest model. This helps estimate how the river system responds to rainfall, land cover, and catchment conditions.
The second stage uses an XGBoost model to classify whether specific locations are likely to flood. This allows flood risk to be translated into spatial maps that are more useful for planning decisions.
Flood risk is not driven by rainfall alone
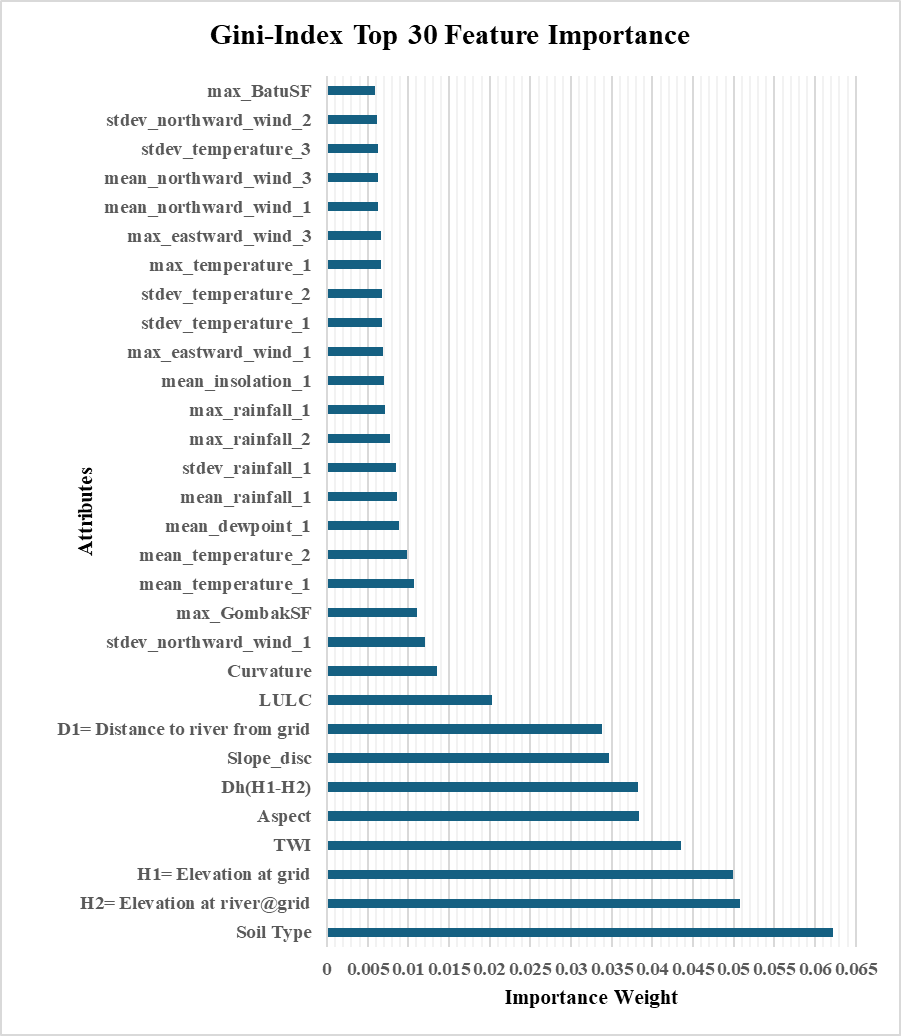
For urban planners, the most important insight is that flood risk is not driven by rainfall alone. The study shows that land cover, built-up areas, elevation, slope, topographic wetness, and proximity to rivers all play major roles in determining where floods occur.
This reinforces the need to treat flood risk as part of spatial planning, zoning, infrastructure design, and development approval.
The case for blue-green infrastructure
The model also highlights the value of preserving permeable and forested areas. Built-up and impervious surfaces increase runoff, while natural land cover can help slow down and absorb stormwater.
This provides a stronger evidence base for blue-green infrastructure, riparian buffers, detention areas, urban wetlands, and stricter controls on development in low-lying flood-prone zones.
From frequency maps to better questions
Another key contribution is the generation of flood frequency maps. These maps can help local authorities identify recurring hotspots, prioritise drainage upgrades, guide road and infrastructure investments, and assess whether proposed developments may increase downstream flood risks.
In practice, this type of machine learning framework can support more proactive planning. It can help planners ask better questions:
- Is this site suitable for development?
- Will new impervious surfaces worsen runoff?
- Which neighbourhoods require flood mitigation first?
- Where should nature-based solutions be protected or restored?
A screening layer, not a replacement for judgment
The study demonstrates that machine learning is not a replacement for planning judgment or hydraulic modelling. Rather, it provides a faster, data-driven screening layer that can strengthen urban planning, climate adaptation, and development control.
For rapidly urbanising cities such as Kuala Lumpur and Selangor, this approach offers a practical pathway toward flood-smart planning — where land-use decisions are guided not only by growth potential, but also by long-term resilience.
Key takeaways
- Flood risk is a land-use and development challenge, not just an engineering one.
- A Random Forest + XGBoost framework turns climate, land-use, soil and terrain data into 30-metre flood insight.
- Land cover, elevation, slope, wetness and river proximity — not rainfall alone — drive where floods occur.
- Machine learning is a fast screening layer that strengthens flood-smart planning and development control.

